Connect Every Asset. Unify Every System.
Deploy AI Everywhere.
.webp)
One platform for connected products, operational data, and intelligent automation, transforming fragmented systems into AI-ready operations.
Enterprises spend millions of dollars and years of time solving the missing layer.
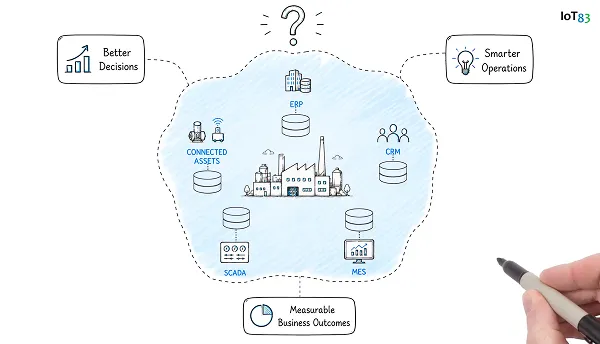
Enterprise systems, operational technologies, and digital initiatives have evolved independently over decades. The result is fragmented architectures impossible to scale, govern, or operationalize.

Fragmented Context
No unified operational view across assets, customers, operations, and business processes. Every team sees a different version of the truth.
Operational Silos
Knowledge remains trapped inside individual systems and teams. Service can't see asset data. AI can't reach operational context.
Slow Innovation
Every new initiative requires additional integrations and custom development. 18–24 months just to get data moving — before building anything valuable.
Limited Scalability
AI, automation, and digital services struggle to operate across disconnected environments. Every new customer deployment is rebuilt from scratch.
A unified workflow where every layer works together, from first connection to AI-driven action. Six capability layers, each one delivering outcomes your enterprise needs.
Data Connectivity
Any device, any system, any protocol — connected without custom code.
Data Governance
Any data becomes business-ready context — automatically, at the source.
Data Processing
Combine siloed data into valuable data collections and analytics.


Data Analysis
From raw data to insight — without building a backend for every question.
Data Visualization
Turn unified data into dashboards, widgets, and embedded analytics — without building a custom UI layer.
LLM Context Creation
Your asset data, made readable by AI agents — for root cause analysis and natural language action.
Trusted by teams at global enterprises
for industrial data and asset ecosystem
















Head of Product, Actiontec
The FLEX83 as an Application Enablement Platform (AEP) was easily customized to handle our sophisticated and high-scale application. The IoT83 team worked with us to deliver this high-quality solution in a very short time.

Networks
IoT83 is revolutionizing the industrial IoT by enabling digital transformation with its secure & scalable platform (Flex83), its application tools, and agile services, streamlining the big data deployments in a cost-effective manner for a faster and increased ROI.

Product Lead
The software is very easy to use & intuitive. FLEX83 has been extremely helpful & committed to nVent success moving the company forward with connecting our legacy installed controller base to the cloud platform.

Electronics
IoT83's cloud platform (Flex83) enabled Vision AI applications on Renesas Virtual Lab's RZ/V series MPUs. It supports RZ/V2M and RZ/V2L evaluation boards, using standard ONNX models and a DRP-AI translator. This solution performs AI inference while delivering metrics like FPS, FPS/Watt, and Inference Time.

American Appliance, OEM
When working with Flex83, you are not just getting a world-class Application Enablement Platform (AEP), you are also gaining access to some of the brightest Dev Minds in the cloud space. It added immense value to our operations.
Global Industrial Manufacturer
We operate across more than a million connected assets, and our problem was never too little data; it was data scattered across too many systems. What worked for us wasn't a rip-and-replace platform, but one that sat on top of what we already ran and pulled everything into a single real-time view. Along with that, we kept full ownership of our data and IP, went from idea to deployment far faster than expected, and at a fraction of the hyperscaler cost.
Head of Product, Actiontec
The FLEX83 as an Application Enablement Platform (AEP) was easily customized to handle our sophisticated and high-scale application. The IoT83 team worked with us to deliver this high-quality solution in a very short time.
Networks
IoT83 is revolutionizing the industrial IoT by enabling digital transformation with its secure & scalable platform (Flex83), its application tools, and agile services, streamlining the big data deployments in a cost-effective manner for a faster and increased ROI.
Product Lead
The software is very easy to use & intuitive. FLEX83 has been extremely helpful & committed to nVent success moving the company forward with connecting our legacy installed controller base to the cloud platform.
Electronics
IoT83's cloud platform (Flex83) enabled Vision AI applications on Renesas Virtual Lab's RZ/V series MPUs. It supports RZ/V2M and RZ/V2L evaluation boards, using standard ONNX models and a DRP-AI translator. This solution performs AI inference while delivering metrics like FPS, FPS/Watt, and Inference Time.
American Appliance, OEM
When working with Flex83, you are not just getting a world-class Application Enablement Platform (AEP), you are also gaining access to some of the brightest Dev Minds in the cloud space. It added immense value to our operations.
Global Industrial Manufacturer
We operate across more than a million connected assets, and our problem was never too little data; it was data scattered across too many systems. What worked for us wasn't a rip-and-replace platform, but one that sat on top of what we already ran and pulled everything into a single real-time view. Along with that, we kept full ownership of our data and IP, went from idea to deployment far faster than expected, and at a fraction of the hyperscaler cost.

Niclas Anderson
VP Sales, Vitronic
The Operational Data Fabric
Once data is ingested, Flex83 continuously transforms, correlates, and governs it — delivering trusted, reusable capabilities for AI, applications, and analytics.
Connect
200+ Connectors. Zero disruption.
Bring any enterprise system, operational technology, or physical asset online through 200+ pre-built connectors without custom code. From SAP and Salesforce to PLCs, historians, and IoT edge devices, every data source joins a single ingestion backbone. Real-time streams, batch files, and device telemetry all flow through one managed foundation.
Transform
Raw data in. Trusted data out.
Once connected, data flows through purpose-built pipelines that process, enrich, and standardize it in real-time and at scale. Flex83 handles stream ingestion into FlexStream, FlexCube, and FlexLake, plus Flink and Spark-powered processing, all configured once and reused everywhere. No re-engineering for every new use case.
Govern
Catalog it. Secure it. Trust it.
Every data asset is automatically cataloged, profiled, and governed before it powers any application or AI model, creating a trusted enterprise-grade foundation you control. The Data Catalog tracks FlexCube tables and FlexLake datasets with full lineage and metadata. Security, API keys, and quality rules are enforced across every layer, not bolted on afterward.
Activate
Ship applications. Deploy AI. Drive outcomes.
Governed, contextualized data is now ready to power any application, AI initiative, or analytics workflow without rebuilding the data layer for each one. Teams launch dashboards and embedded analytics through the Widget and Dashboard Library. AI engineers access the Knowledge Hub, ML Studios, and Model Registry to build and deploy intelligence at scale.Cortex AI brings a natural language interface across all operational data.
Own and Scale
Your cloud. Your data. Your IP.
Flex83 runs in your cloud, private, public, or hybrid, with full infrastructure control and zero vendor lock-in. The Platform Launcher lets your team spin up, configure, and manage platform environments without DevOps overhead: provision clusters, configure cloud targets, and track run history from a single control plane. Your data and your IP, always.
What enterprises unlock with Flex83.
Not features. Measurable outcomes across every dimension that matters to your enterprise.

Unified Namespace
Data Layer
One trusted operational data foundation across all systems, assets, and applications. Every team works from the same truth — no more silos, no more reconciliation.

Solution & Portfolio Acceleration
Pre-built platform capabilities replace 25+ point solutions. Launch new connected product lines, AI applications, and digital services without rebuilding the foundation each time.

Time to Market
From 18-month integration cycles to weeks. Connected products ship faster. New customers onboard in days. AI initiatives launch in sprints, not quarters.

Total Cost of Ownership
Replace fragmented vendor contracts with one platform. Reduce infrastructure costs, eliminate integration overhead, lower engineering burden, and reclaim margins.

Cloud agnostic
Deploy on AWS, Azure, GCP, private cloud, or at the edge — with no architecture changes. Move freely across providers. Your infrastructure, your rules, zero vendor lock-in.

Revenue & Business Growth
Transform from equipment seller to software-led service provider. New subscription revenue, outcome-based models, and higher customer lifetime value built on operational intelligence.
Resources
.webp)
.webp)
Industrial OEMs Are Becoming Software Companies — Most Haven’t Updated Their Platform Strategy Yet